Random Forest
4 min read

Imagine yourself in a state of confusion, torn between 3 movies on your watchlist, unable to decide which one to watch.
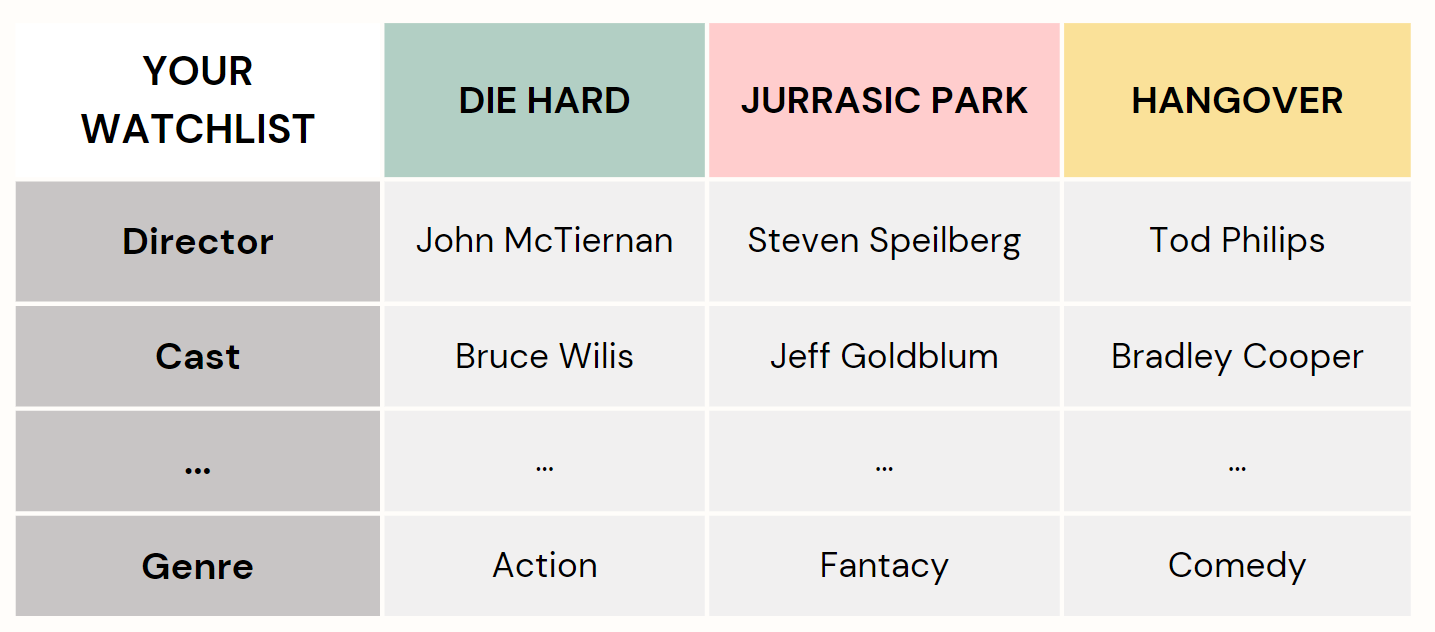
Seeking guidance, you turn to your trusted friends, knowing that their opinions will help you make a decision. Each friend approaches the movie recommendation process differently by asking you random questions tailored to their biases.

Your friends evaluate different aspects such as genre, director,
actors, etc. associated with each movie. They also apply their own unique lens and personal
preferences to ask you questions and analyze the available choices before offering their
input.
In technical terms, they become individual decision trees. Meanwhile, you
gather their
distinct viewpoints, combine their opinions, and make the ultimate movie prediction, playing
the role of an arbitrator.
A decision tree is like a game of 'yes' or 'no' questions!
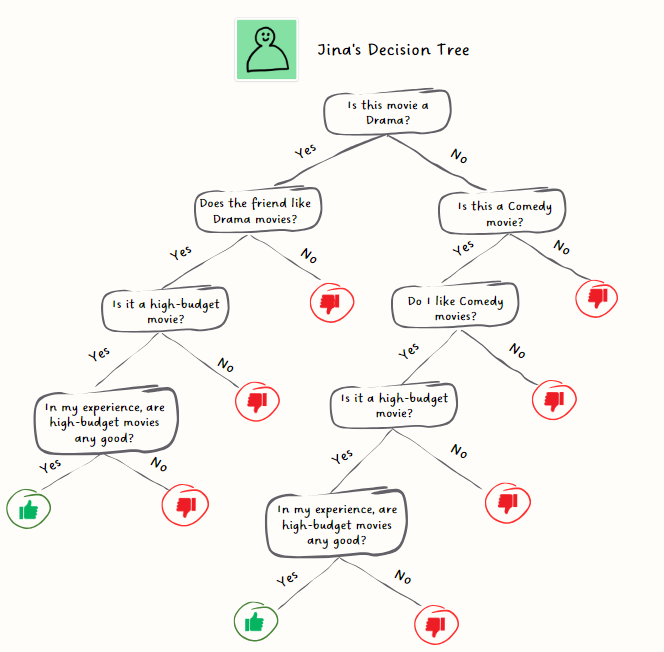
After asking a series of questions for each of the movies Jina arrives at the given ratings for the movies:

Just like your friend Jina, all your other friends would vote for each of the movies. Then you, as an arbitrator, would gather suggestions from all the friends (decision trees) and hold a vote.
Each decision tree has a vote, and the movie with the most votes becomes the final prediction.
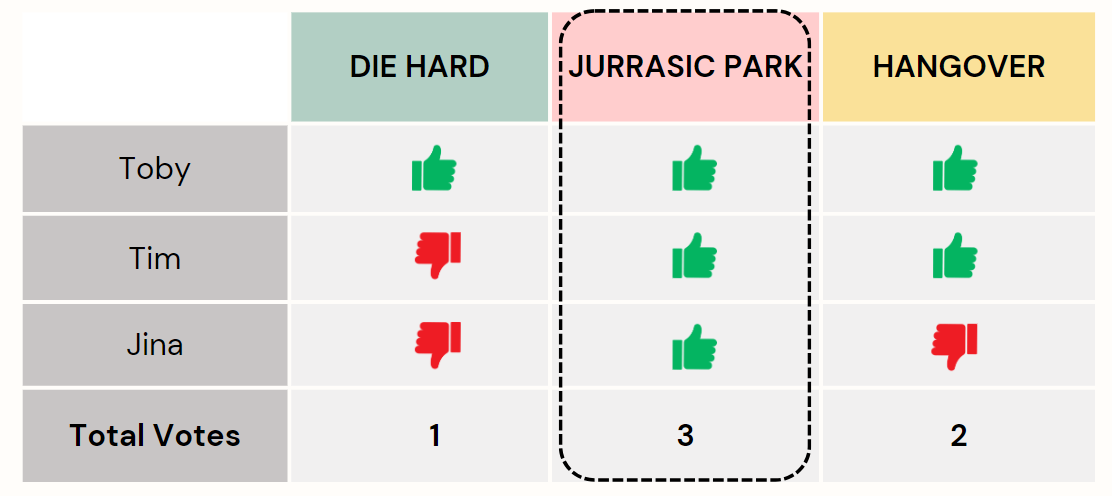
It is called a Forest since it's a collection of individual
decision trees.
But why the word “random” in random forest? The randomness comes into play in two ways:
- When evaluating movies, each friend focuses randomly on a specific aspect they deem crucial for predicting a good movie.
- Randomness emerges from each friend's limited exposure to movies. Each friend in their lifetime might have seen different sets of movies. This diversity mitigates individual biases and limitations.
So, by combining the opinions of multiple decision trees, the Random Forest ensures more accurate and robust movie prediction. It's like having a group of friends with diverse tastes, coming together to help me make the best movie choice!
A Real-world business case to drive the point home
Imagine a bank that holds detailed data on borrowers, notably their loan repayment history.
The bank seeks to develop a tool that can guess how likely are future borrowers able to
repay their loans. It's like a system to rate the risk of lending money to people.
Utilizing a random forest model, we can assess various factors or 'features'. These features
may include credit score, employment status, income, debt-to-income ratio, loan amount,
credit history (like late payments or defaults), repayment history, and more. Other
considerations might include age, marital status, education, and location.
In a Random Forest model, decision trees are trained using random samples from the data,
focusing on different feature combinations. Although individual trees might have biases,
their collective predictions form a robust tool for gauging loan default risks. The reason
Random Forest performs well with new and unseen data lies in its approach of allowing each
tree in the forest to observe only a random subset of data and features. This method enables
the model to make accurate predictions even in unfamiliar scenarios.
Have any burning questions or specific topics you'd like us to explore? Share your thoughts at hi@simplifyingstuff.com
Share